
当 Claude、GPT、Qwen 这样的语言模型变得越来越强,业界似乎默认了一条进步路线:把模型做大。但 HarnessX 的作者们提出了一个不同的问题——如果 Agent 的瓶颈不在模型本身,而在模型与任务之间的"中介层"呢?

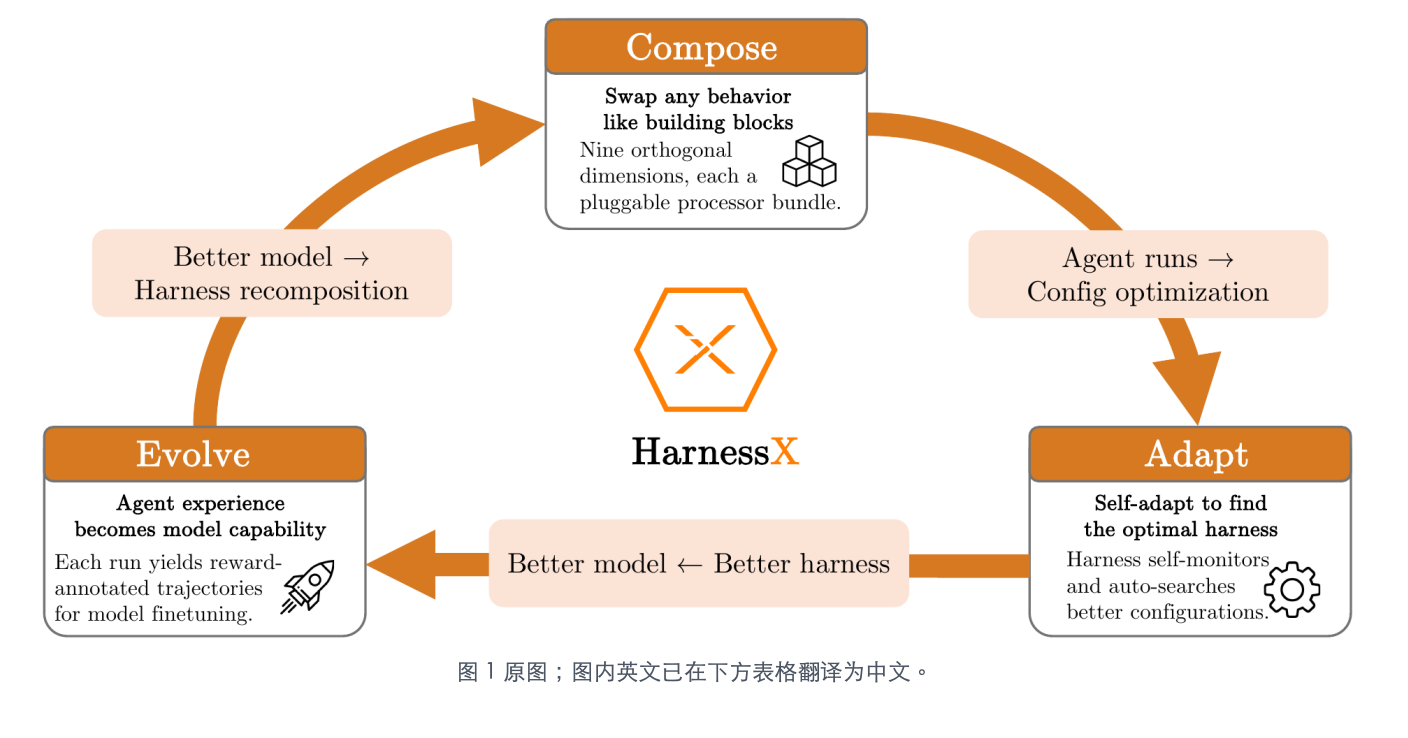
这篇来自 Darwin Agent Team 的论文给出了一个完整的工程回答:把 runtime harness(提示词、工具、记忆、控制流这一整套中介机制)当作一等公民,让它像积木一样被组合,像代码一样被演化,像模型一样被训练。实验数据相当惊人:在五个 benchmark 上,HarnessX 带来平均 +14.5% 的绝对提升,最高 +44.0%。更耐人寻味的是,基线越低,提升越大 ——这意味着弱模型反而是最能从 harness 演化中受益的对象。
一、Harness:被忽视的 Agent 性能杠杆
现代 Agent 的能力并不只取决于底层模型。决定任务表现的关键因素,是包裹在模型周围的那一层 harness——它负责把任务表示成模型能理解的形式,决定外部工具如何被调用,控制中间决策如何在不同步骤间传递。可以把它理解为 Agent 的"操作界面"。
问题在于,目前 harness 的工程化方式相当原始:
第一,它是手工编写的,且高度静态。每换一个模型或任务域,工程团队就得重新写一套 scaffold,缺乏从经验中自动改进的机制。
第二,它的架构高度纠缠。提示词模板、工具 wrapper、重试策略、记忆模块往往被混在同一个代码路径里,改动一处就可能在别处引发 silent regression;跨领域复用退化为复制粘贴,而不是真正的组合。
第三,harness 改进与模型训练相互脱节。收集到的轨迹数据被丢弃,没有进入模型训练;模型的进步也不会回流到 harness 设计。
HarnessX 的核心思想,就是把这三个缺口同时补上:把 harness 形式化为可组合、可替换、可演化的一等对象,并通过统一的优化循环与模型训练耦合。
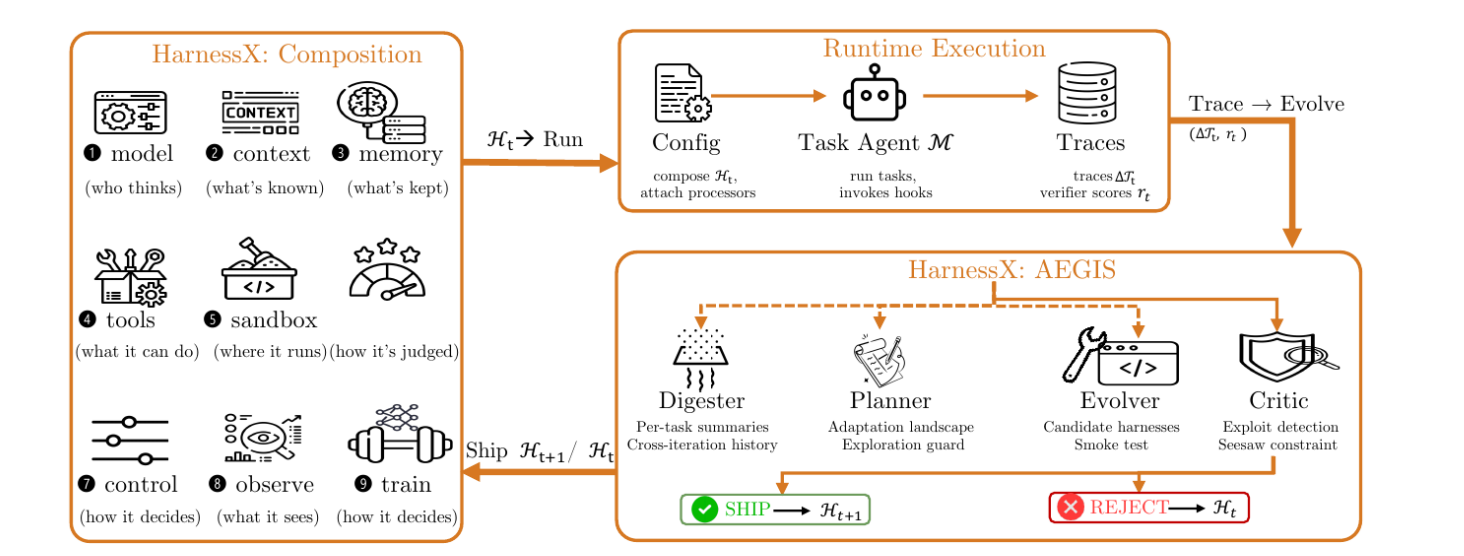
二、HarnessX 的三层架构
HarnessX 不是一个单点方案,而是一个统一的 foundry,包含三层递进的设计:
┌─────────────────────────────────────────────┐ │ Harness-Model 协同演化 (Co-Evolution) │ ├─────────────────────────────────────────────┤ │ Harness 适应 (AEGIS 引擎) │ ├─────────────────────────────────────────────┤ │ Harness 组合 (Composition Foundation) │ └─────────────────────────────────────────────┘
2.1 组合层:把 Harness 拆成可替换的积木
HarnessX 把 harness 定义为一对对象 $\mathcal{H}=(\mathcal{M},\mathcal{C})$,其中 $\mathcal{M}$ 是模型配置,$\mathcal{C}$ 是 harness 配置。两者关注点正交:模型决定"谁在思考",harness 决定"如何行为"。
harness 配置进一步分解为 $\mathcal{C}=(\mathbf{P},\mathbf{S})$:
- $\mathbf{P}: \mathcal{Hook}\to \mathrm{List}[\mathit{Processor}]$:以 hook 为索引的 processor 列表
- $\mathbf{S}$:tool registry、tracer、workspace、sandbox、plugin 等共享 slot resources
每个 hook 对应 run loop 中的一个生命周期事件,下表是完整的 hook 契约:
| Hook | Event Type | 允许修改 |
|---|---|---|
| task_start | TaskStartEvent | system prompt |
| step_start | StepStartEvent | 结构化历史编辑 |
| before_model | BeforeModelEvent | 最后一条用户内容;追加一条用户消息 |
| after_model | ModelResponseEvent | response 内容、tool calls |
| before_tool | ToolCallEvent | tool input、approval flag |
| after_tool | ToolResultEvent | tool result |
| step_end | StepEndEvent | 只读 |
| task_end | TaskEndEvent | 只读 |
processor 遵循统一的协议:
async def process(self, event: Event) -> AsyncIterator[Event]: """消费一个事件,产出零个或多个事件"""
五种语义结果:pass-through(透传)、transform(转换)、split(拆分)、intercept(拦截)、interrupt(抛异常终止)。这个受限接口保证了任意 hook 上的 processor 都能按顺序组合,插入或移除都不影响类型正确性。
更进一步,每个 processor 携带类级元数据:
_singleton_group:命名互斥类,确保每组最多一个 processor_order:hook 内排序提示(PRE / NORMAL / POST)_after:对其他 singleton group 的软依赖列表
这套机制让 harness 演化成为类型安全的操作:AEGIS 可以插入新 processor、替换旧 processor、或完全移除某个 processor,而无需触碰其他部分。
2.2 九维分类法:覆盖完整行为空间
HarnessX 沿九个正交维度组织行为空间:
| 维度 | 作用 |
|---|---|
| D1 Model selection | 决定哪个模型服务哪个角色 |
| D2 Context assembly | 决定每一步呈现给模型什么上下文 |
| D3 Memory management | 管理跨 step 和跨 session 的记忆 |
| D4 Tool ecosystem | 控制 agent 可调用的工具集 |
| D5 Execution environment | 决定工具副作用在哪里发生 |
| D6 Evaluation and reward | 指定如何评判结果 |
| D7 Control and safety | 强制规则,防止 agent 循环或超支 |
| D8 Observability | 记录每个事件、模型调用和工具调用 |
| D9 Training bridge | 把执行轨迹转化为 RL 训练记录 |
实践中 AEGIS 演化时的编辑跨越全部九个维度,但 D2(context assembly)和 D4(tool ecosystem)是最频繁的编辑目标;D8 提供轨迹底座供 AEGIS 推理;D9 为协同演化提供训练记录。
三、AEGIS:把 Harness 演化建模为符号空间中的强化学习
组合层提供了类型化、可替换的 harness;AEGIS 是把这个 harness 演化出来的引擎。
3.1 操作镜像(Operational Mirror)
关键洞见是:harness 演化在结构上可以映射到符号空间中的强化学习。
| RL 概念 | 符号空间对偶 | AEGIS 实现 |
|---|---|---|
| Policy $\pi$ | Harness-update procedure | $\pi_{\mathrm{evo}}$,四阶段 pipeline |
| State $s_t$ | $(\mathcal{H}_t, \mathcal{T}_t)$ | Harness 配置 + trace store |
| Action $a_t$ | 类型化 harness edit | Builder operation + change manifest |
| Feedback | Trace $\tau$ + verifier score $r$ | Observability layer |
| Update | $\mathcal{H}_{t+1}\leftarrow U(\widetilde{\mathcal{H}}_t, \mathcal{T}_t, r_t)$ | 确定性 acceptance gate |
形式化定义如下:
Definition 1 (Harness Configuration) :$\mathcal{H}=(c_1,c_2,\ldots,c_9)$,每个 $c_i\in\mathcal{C}_i$ 实例化九个行为维度之一。
Definition 2 (Harness Edit) :$e:\mathcal{H}\to\mathcal{H}$,修改一个或多个维度,保持类型契约。action space $\mathcal{E}$ 是离散但开放的:每个 edit 都是由 meta-agent LLM 生成的代码级 artifact(新的 processor 源码、修改后的 prompt template、重新配置的 tool registry),而不是从预枚举集合中选择。
Definition 3 (Operational Mirror) :$(\mathcal{H}, \mathcal{E}, \mathcal{R}, \mathcal{T})$,构成 harness 层的 MDP。harness 配置是 state,类型化 edit 是 action,轨迹加 verifier score 构成 feedback。
这个映射的威力在于,它不是类比,而是预测性:它把三种熟悉的 RL 病理,reward hacking、catastrophic forgetting、under-exploration,转化为 harness 演化中的具体设计风险。
3.2 三种病理与对应防御
Reward hacking :标准 RL 中 reward hacking 利用 reward signal 的漏洞完成任务。符号 harness 演化放大了这种风险:evolver 可以直接瞄准验证协议,把 benchmark 答案嵌入 prompt、利用 verifier 的格式规律、引入 processor 把输出重写成符合 verifier 期望的形式。AEGIS 用 Critic 模块防御 。
Catastrophic forgetting :修复故障模式 A 的 edit 可能悄悄让模式 B 退化,因为影响会通过共享 context、tools、memory policy、control rule 传播。没有显式 regression checking,只根据失败任务轨迹进行条件化的 evolver 无法区分局部增益和全局退化。AEGIS 用确定性 gating layer 防御 。
Under-exploration :pipeline 偏向低风险局部 edit——prompt 重写、tool description 微调、轻量 control-flow 调整。这些 edit 成本低、经常能通过 gating 不退化,导致 Planner 假设继续偏向同一邻域。结构性变化(拆分 agent、替换控制策略、采用新 memory 架构)需要刻意形成假设。AEGIS 用 Planner 防御 。
3.3 四阶段 Pipeline
AEGIS 由四个阶段组成,全部由同一个 meta-agent LLM 驱动并选择性调用:
┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐ │ Digester │ → │ Planner │ → │ Evolver │ → │ Critic │ → │ Gate │ │ 轨迹压缩 │ │ 适应规划 │ │ 编辑生成 │ │ 评估候选 │ │ 确定性裁决│ └──────────┘ └──────────┘ └──────────┘ └──────────┘ └──────────┘
每个阶段都有自己的 continuation condition,可能让本轮短路(no-op),只有 Critic 和确定性 gate 是强制的——任何候选都必须通过二者才能 ship。
Digester :把每条原始轨迹压缩成结构化 per-task summary。以 GAIA 单轮为例,103 个任务 pass@2 产生约 1000 万 token 的原始轨迹,朴素截断会丢掉诊断信号。Digester 输出二值结果、失败类别、牵涉组件 identifier、支持性证据摘录,同时连接跨迭代历史。
Planner :构建 adaptation landscape——哪些任务失败、尝试过哪些 edit、哪些 edit 类型仍未尝试。这是抵抗 under-exploration 的主防线:把结构性变化(工具添加、processor 重写、memory policy redesign)和增量 prompt edit 一起考虑。
Evolver :生成候选 harness ${\widetilde{\mathcal{H}}t^k} $,每个候选表示为对当前 harness 的类型化 builder operation,并携带 change manifest(编辑过的组件、预期行为效果、预计改进或退化的任务)。}^{K_t
Critic + Gate :Critic 通过比较 manifest 和 trace evidence 评估候选,判断 edit 是否会通过 shared state 或 control flow 造成非局部风险,最多发起一轮 revision request。确定性 gate 按序执行 acceptance check:manifest 完整性、配置归一化、build/smoke test、seesaw constraint。这把 LLM 判断和 acceptance 解耦——无论 Critic 如何建议,只有确定性检查决定 ship。
完整的演化循环算法如下:
Algorithm 1: AEGIS Harness 演化循环 输入:初始 harness H_0、meta-agent M、预算 T、patience P、阈值 α 输出:演化后的 harness H_{t+1}、trace store T_{t+1}
- 初始化 T_0 ← ∅,idle ← 0
- 对每轮 t = 0, 1, ..., T-1: a. 抽样 batch B_t;运行 H_t 得到 traces ΔT_t;更新 T_{t+1} b. Digester: 生成证据与 actionability。若 a_t < α,no-op,idle++ c. Planner: 从证据生成 adaptation landscape。若为空,no-op d. Evolver: 生成 K_t 个候选 harness 及 manifest。若无候选,no-op e. Critic & Gate: Critic 排序候选;确定性 gate 按序测试 第一位通过者被提交 f. 若无候选通过,保持旧 harness,idle++ 若 idle >= P,停止
- 返回 H_{t+1}, T_{t+1}
3.4 Variant Isolation:突破单 Harness 的天花板
当任务需要冲突行为时,一个改进某个子集的 edit 可能让另一个子集退化;seesaw constraint 保护稳定性但丢掉局部有益变化。
Variant Isolation 通过维护最多 $K$ 个 harness variants ${\mathcal{H}_t^{(1)},\ldots,\mathcal{H}_t^{(V_t)}}$($V_t\le K$),并把每个任务路由到对该任务 cluster 历史成功率最高的 variant 突破这一限制。这一机制称为 Ensemble Routing。
- 若 edit 改进部分任务且不导致任何退化,则应用到目标 variant
- 若 edit 改进一个子集但让另一些退化,则 fork 一个新 variant
- 一旦存在多个 variant,seesaw constraint 作用域变为 per-variant
实验验证了三点预测:聚合轨迹不退化(peak=final);更晚达峰但保持探索;总 token 消耗更低。

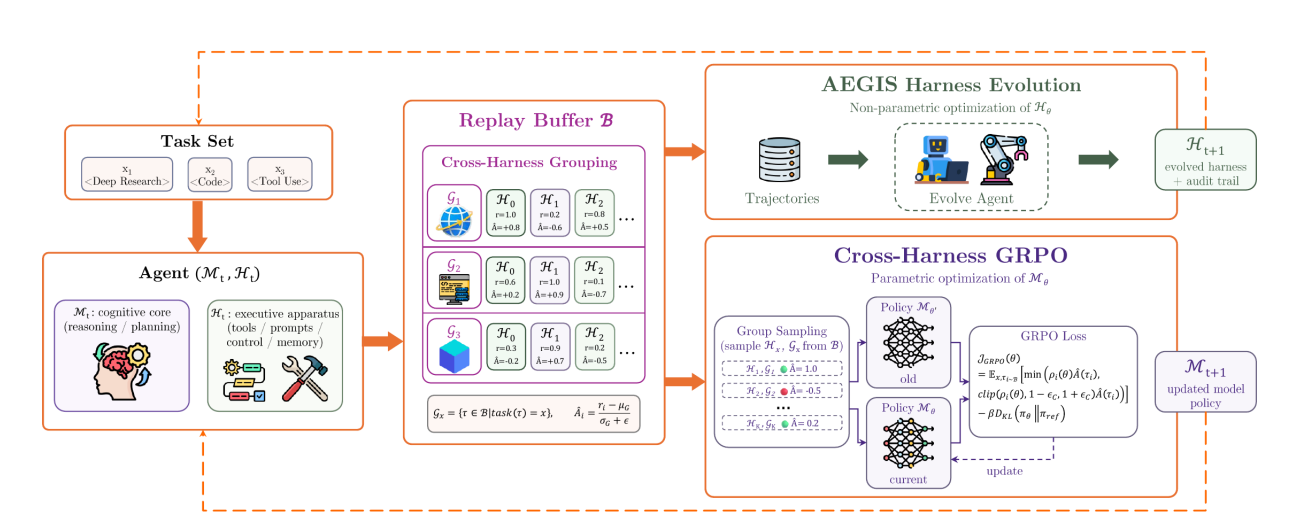
四、Harness-Model 协同演化
仅演化 harness 已经能带来显著收益,但收益对更弱、更小的 task agent 最大。协同演化不是替代这条路径,而是在第二个轴上扩展它。
对能力受限的小模型,harness 演化最终会遇到 scaffolding ceiling :一旦 harness 暴露了正确的工具、上下文和控制流,约束就变成模型本身是否真的能利用它们。对称地,在固定 harness 下训练模型会遇到 training-signal ceiling :当 scaffold 从不暴露能激发新能力的上下文时,新能力不会被使用。
协同演化正是针对这个瓶颈:在演化 harness 的同一循环中训练模型,让 agent 沿两个轴同时改进。
4.1 协同演化 Iteration
共享 replay buffer B │ ▼ ┌────────────────────┐ │ Agent (M_t, H_t) │ ──── 轨迹 τ, 奖励 r ────► B │ 在 batch B_t 上运行 │ └────────────────────┘ │ ├────────────────────────────┐ ▼ ▼ ┌────────────────┐ ┌────────────────────┐ │ AEGIS 演化 │ │ Cross-Harness GRPO │ │ H_{t+1} │ │ M_{t+1} │ └────────────────┘ └────────────────────┘
具体步骤:
- Rollout :用 $(\mathcal{M}_t, \mathcal{H}_t)$ 运行 adaptation batch $B_t$;observability layer 记录完整 trace $\tau_i$
- Verification :固定 verifier 给出标量 reward $r_i$
- Buffer insertion :把带分 trace 连同产生它的 harness version 加入共享 buffer $\mathcal{B}$
- Harness evolution :$\mathcal{H}_{t+1}\leftarrow\text{AEGIS}(\mathcal{H}_t, \mathcal{B})$
- Behavior log-probabilities :用 $\mathcal{M}_t$ 对新加入的 traces 跑 forward pass,缓存 token-level log-probabilities
- GRPO update :$\mathcal{M}_{t+1}\leftarrow\text{GRPO}(\mathcal{M}_t, \mathcal{B})$
- Advance :用 $(\mathcal{M}{t+1}, \mathcal{H})$ 回到步骤 1
4.2 Cross-Harness GRPO
关键设计是 cross-harness grouping criterion :所有共享同一 task identifier 的轨迹组成一个 GRPO group,不管它们由哪个 harness 或模型 checkpoint 产生:
$$\mathcal{G}_x={\tau_i\in\mathcal{B}\mid \text{task}(\tau_i)=x}=\bigcup_k{\tau\sim\text{Agent}(\mathcal{M}_k,\mathcal{H}_k,x)}$$
Group-relative advantage:
$$\hat{A}(\tau_i)=\frac{r_i-\mu(\mathcal{G}_x)}{\sigma(\mathcal{G}_x)+\epsilon}$$
Policy objective:
$$\mathcal{J}{\text{GRPO}}(\theta)= \mathbb{E})$$}} \left[ \min\left(\rho_i(\theta)\hat{A}(\tau_i), \text{clip}(\rho_i(\theta),1-\epsilon_c,1+\epsilon_c)\hat{A}(\tau_i)\right) \right] -\beta D_{\text{KL}}(\pi_\theta|\pi_{\text{ref}
其中 $\rho_i(\theta)=\frac{\pi_\theta(\tau_i\mid x)}{\pi_{\theta_{\text{old}}}(\tau_i\mid x)}$。
演化中的 harness 作为模型 RL 的结构化探索算子:每个新版本给任务采样分布注入一种不同的行为模式,advantage 会把模型推向 verifier 评分最高的模式。
4.3 混合策略 Buffer 上的 Off-Policy Training
Replay buffer 本质上是 off-policy 的:buffer distribution 不匹配正在更新的 policy。解决方案是在 buffer insertion 时用 $\mathcal{M}_k$ 跑一次 forward pass,把 token-level log-probabilities 物化并缓存到磁盘。
FIFO eviction 把 buffer 限制在近期轮次,因此每个 cached $\pi_{\theta_{\text{old}}}$ 都来自 $\pi_\theta$ 的有限窗口,off-policy bias 有界。
更重要的是:同一批 trajectories 同时驱动 AEGIS harness update 和 cross-harness GRPO model update。GRPO 通过 replay 消费这些 traces,不产生自己的 rollout。添加 model update 的边际成本仅限于:每条 trajectory 一次 cached forward pass,以及 gradient steps 本身。二者都不需要 rollout。没有任何 trajectory 是专门为了训练模型而生成的。
五、实验验证
5.1 实验设置
在五个 benchmark 上评估 HarnessX:
| Benchmark | Domain | Sampled Tasks | Verifier |
|---|---|---|---|
| GAIA (Level 1-3) | 多步检索 | 103 | Exact match |
| ALFWorld | 具身规划 | 134 | Goal completion |
| WebShop | Web 交互 | 100 | Attribute match |
| $\tau^3$-Bench | 多轮对话 | 3 domains | Rule compliance |
| SWE-bench Verified | 软件工程 | 55 | Patch resolution |
最多运行 $T=15$ 轮演化,连续 $P=3$ 轮没有 shipped edit 时提前停止。Meta-agent 默认为 Claude Opus 4.6;task agent 覆盖三个家族:Claude Sonnet 4.6、GPT-5.4、Qwen3.5-9B。
Baselines: 1. Static Harness :已发布 benchmark-specific prompt 和 tool definition 构造的 HarnessX 配置 2. Claude Code SDK :单 agent evolver,每轮一个 LLM session,替代四阶段 pipeline
5.2 主要结果
| Benchmark | Task Agent | Initial | Evolved | Δ | Best Round |
|---|---|---|---|---|---|
| ALFWorld | Claude Sonnet 4.6 | 83.6 | 94.8 | +11.2 | 7 |
| ALFWorld | GPT-5.4 | 76.9 | 97.8 | +20.9 | 4 |
| ALFWorld | Qwen3.5-9B | 53.0 | 97.0 | +44.0 | 9 |
| WebShop | Claude Sonnet 4.6 | 60.0 | 76.0 | +16.0 | 7 |
| WebShop | GPT-5.4 | 55.0 | 73.0 | +18.0 | 8 |
| WebShop | Qwen3.5-9B | 36.0 | 49.0 | +13.0 | 7 |
| GAIA | Claude Sonnet 4.6 | 73.8 | 83.5 | +9.7 | 11 |
| GAIA | GPT-5.4 | 73.8 | 73.8 | 0.0 | 4 |
| GAIA | Qwen3.5-9B | 20.3 | 37.4 | +17.1 | 4 |
| SWE-bench Verified | Claude Sonnet 4.6 | 76.4 | 87.3 | +10.9 | 3 |
| SWE-bench Verified | GPT-5.4 | 45.5 | 63.6 | +18.2 | 3 |
| SWE-bench Verified | Qwen3.5-9B | 23.6 | 41.8 | +18.2 | 2 |
| $\tau^3$-Bench | Claude Sonnet 4.6 | 89.6 | 95.0 | +5.4 | — |
| $\tau^3$-Bench | GPT-5.4 | 76.2 | 90.7 | +14.5 | — |
| $\tau^3$-Bench | Qwen3.5-9B | 93.5 | 94.6 | +1.1 | — |
AEGIS 改进了 15 个 model-benchmark 配置中的 14 个 ,平均提升 +14.5% ,最高 +44.0% 。唯一停滞的是 GAIA / GPT-5.4($\Delta=0.0$),原因是单 harness 演化在异质任务集上的基本限制——variant isolation 消融解决了这一问题。
最关键的发现是 inverse-scaling effect :跨 benchmark 看,最弱 task agent Qwen3.5-9B 一贯收益最大——ALFWorld +44.0%(基线 53.0%)、GAIA +17.1%(基线 20.3%)、SWE-bench Verified +18.2%(基线 23.6%)。更强模型收益更小。这说明演化出的 harness 填补了弱模型无法自我纠正的行为缺口。
收敛速度跟 failure-mode 集中度相关:ALFWorld GPT-5.4 在 R4 达峰,SWE-bench Verified 所有 agent 在 R2-R3 达峰——两者失败集中在一两种 component type;GAIA Sonnet 4.6 需要 11 轮,因为失败横跨 prompt、tool、processor、configuration 四种 component type。
5.3 演化策略比较
主实验使用 Global strategy:在所有任务上演化单个 harness。在 GAIA 上的对比:
| Strategy | Final (%) | Peak (%) | Final-Peak | Tokens |
|---|---|---|---|---|
| Ensemble (up to K variants) | 87.4 | 87.4 | 0.0 | 107.8M |
| Global (single harness) | 49.5 | 73.8 | -24.3 | 143.7M |
Global strategy 在 R4 早早达到 73.8% 峰值,随后持续退化,后续 edit 引入了低于阈值的 regression,在 pass@2 的二值信号下单独不可见,却累积成 aggregate decline。Peak-final gap 为 -24.3%,远超每轮 binomial 95% confidence interval(约 ±8.5%),确认是 catastrophic forgetting 而非评估噪声。
Ensemble routing 把 GAIA GPT-5.4 从 $\Delta=0.0$ 提升到 +13.6%(87.4%),且不退化,同时 token 消耗更低(107.8M vs 143.7M)。
5.4 Meta-Agent 有效性
为分离 evolver 架构和基础设施,用单 agent CC SDK evolver 替代四阶段 AEGIS pipeline:
| Evolver | Accuracy (%) | Best Round | Tokens |
|---|---|---|---|
| AEGIS | 87.4 | R14 | 107.8M |
| CC SDK | 86.4 | R12 | 123.1M |
1.0% 的 accuracy 差距落在一个 standard error($n=103$ 时约 3.3%)内。但 CC SDK 消耗约 14% 更多 token——这归因于 Digester 压缩:把约 10M raw trace tokens 压缩到约 10K structured summaries。
含义是:在这个 meta-agent 能力水平下,四阶段分解贡献的是效率(约少 12% token)和可解释性(可审计的中间 artifact),而不是可测的 accuracy 改进。

5.5 协同演化
在 GAIA 和 WebShop 上用 Qwen3.5-9B task agent 比较 harness-only 演化和协同演化:
| Benchmark | Harness-only Peak | Co-Evolution Peak | Δ |
|---|---|---|---|
| GAIA | 37.4% | 41.7% | +4.3% |
| WebShop | 49.0% | 54.0% | +5.0% |
两条曲线在 joint training 生效前(即 R4 前)基本重合,随后分离;余下 run 中协同演化始终不低于 harness-only。差距持续到最终轮:GAIA 从 36.4% 到 39.8%,WebShop 从 46.0% 到 50.0%。
协同演化突破 scaffolding ceiling:cross-harness GRPO 让模型内化 successive harness versions 的策略,因此后续 edit 构建在已学习行为上,而不只是补偿固定模型的内在限制。
5.6 失败分析
三个 case study 验证了操作镜像预测的三个病理:
Reward hacking(GAIA,Sonnet 4.6,R10) :pipeline ship 了一个 composite edit,覆盖 tool、prompt、configuration,accuracy 从 74.8% 提到 79.6%。R11 trace analysis 显示,该工具确实为多数新通过任务修复了 retrieval,但有一部分任务是利用 verifier 的格式规律而通过。R12 guard 限制该工具在输出能被第二条 retrieval path 交叉检查的任务上。
Catastrophic forgetting($\tau^3$-Bench,Sonnet 4.6,Telecom,R7) :Telecom 上连续五轮 ship 同类型 prompt/processor edit,每次追加一个 "reminder" rule。Compliance 从 89.5% 提升到 R4 的 100%,随后第六条 reminder 通过跨规则冲突让 compliance 从 94.7% 降到 80.7%(-14.0%)。该 regression 逃过 seesaw constraint,因为 pass@2 只记录 per-task binary flip,不记录低于阈值的 coupling。R9 时 pipeline 自我纠正:Planner 诊断集中模式,提出结构性 edit 替换冲突的 reminder stack。
Under-exploration(ALFWorld,Sonnet 4.6,R4-R7) :R4 到 R7 之间 pipeline 主要 ship prompt-level edit,每轮增益低于 1%。Ship-prediction accuracy 从 R3 的 80% 降到 R7 的 0%,说明 prompt-space 已耗尽。R6 唯一的 processor-level change ship-prediction accuracy 只有 14%,说明 Planner 缺少足够的 structural-edit history 来校准 prompt neighborhood 之外的假设。
六、讨论:组合结构为什么对演化重要
Global strategy 在 GAIA 上 R4 早早达到 73.8% 峰值,随后跌到 49.5%。Global 使用 HarnessX 的类型化组件,但没有利用它们做 isolation;每个 edit 都对所有任务一起评估。
这种关系类似类型系统:类型不会自动生成正确程序,但会让错误程序可检测。类似地,类型化组件不会阻止坏 edit,但会让其作用范围显式化,从而允许独立变体。
Trace 丰富度也至关重要:检测 R10 ship 的 reward hacking,需要检查 improvement 如何发生;检测 R4-R7 的 under-exploration,需要跟踪 edit-type distribution 和 ship-prediction accuracy。仅凭标量 reward,三个病理都不可检测。
操作镜像是设计启发式,不是形式框架。经典 RL 收敛保证需要充分探索 state-action space,而当 state 是符号 harness configuration、action 是开放式代码 edit 时,这个条件无法满足。因此,镜像当作设计 checklist,而不是预测理论。
七、局限
论文坦诚指出了五个限制普遍性的约束:
- 没有 held-out evaluation :所有报告增益都在用于演化的同一任务集上测量,数字包含 selection bias 和潜在 overfitting
- 只有离散 action space :所有实验使用具有离散文本 action space 的 agent,连续 action space(如机器人控制)尚未测试
- 闭源 meta-agent :AEGIS 需要能做多文件代码生成、结构化 trace analysis 和多步规划的 meta-agent;接近这一能力水平的 open-weight 模型尚未作为 meta-agent 测试
- Joint control assumption :协同演化需要同时控制 harness evolution 和 model training;实践中这两个关注点常由不同团队负责
- Benchmark 覆盖 :SWE-bench Verified 使用 55-task subsample,$\tau^3$-Bench 只评估三个 domain;inverse-scaling effect 可能无法泛化到更大评估集
八、结论
HarnessX 提出一个可组合的运行时 foundry,把 harness 视为模型和环境之间的一等接口。这个接口可以由类型化 primitive 组合,可以从执行轨迹中演化,也可以在统一改进循环中与模型训练耦合。
跨五个 benchmark 和三个模型家族,HarnessX 通过组合底座上的轨迹驱动演化,实现最高 +44.0% 的提升,在 15 个配置上平均 +14.5%;协同演化在两个 benchmark 上比 harness-only evolution 额外增加 +4.7%。
这些结果说明,agent 进步不必只依赖模型 scaling。从执行反馈中组合并演化运行时接口,是一条互补且可操作的杠杆,尤其适用于能力受限 agent——因为它们的 harness-level gain 最大。
当一个 9B 的小模型通过 harness 演化在 ALFWorld 上达到 97.0%(超过 GPT-5.4 的 97.8% 和 Sonnet 4.6 的 94.8%),我们不得不重新思考:Agent 的天花板,到底是由模型大小决定的,还是由它与世界的接口决定的?
